数据分析案例:Olist 巴西电商公共数据集
数据集来源:
这是真实的商业数据,所有商店和合作伙伴的文本都已替换为《权力的游戏》中的家族名称。
了解 Olist 商业模式
Olist 是一个 B2B2C 的平台,为长尾中小商家提供将 SKU 一站分发到各大电商平台的服务,为他们提供在各大电商平台的信用背书,降低中小商家入驻大平台的门槛。对于大平台来说,Olist 是一个超级大卖家,依托众多中小商家,提供了海量 SKU。 Olist 的利润主要来自 SaaS 软件的订阅费(月费/年费)和每笔订单的佣金抽成。
上述只针对 2016~2018 年间的 Olist,现在的 Olist 的业务版图已经扩展了非常多。
选定北极星指标
任何商业公司的最终目的都是盈利,所以个人思路是:从利润开始层层拆分,每层只拆分成长性更高的那个指标。
- 第一次拆分:$利润 = 营业额 \times 利润率$
- 第二次拆分:$营业额 = 订阅费收入 + 佣金收入$
- 第三次拆分:$佣金收入 = 总交易额(GMV) \times 佣金率$
再往下拆会不得不产生信息损失,导致决策信息失真,所以这里选择 GMV 作为北极星指标。
理解数据集结构
数据源网站已经给出了所有字段的准确语义和 Data Schema,这里根据已有信息画出 ER 图即可。
erDiagram
olist_customers {
string customer_id PK
string customer_unique_id UK
string customer_zip_code_prefix
string customer_city
string customer_state
}
olist_orders {
string order_id PK
string customer_id FK
string order_status
timestamp order_purchase_timestamp
timestamp order_approved_at
timestamp order_delivered_carrier_date
timestamp order_delivered_customer_date
timestamp order_estimated_delivery_date
}
olist_order_items {
string order_id PK, FK
int order_item_id PK
string product_id FK
string seller_id FK
timestamp shipping_limit_date
float price
float freight_value
}
olist_products {
string product_id PK
string product_category_name
int product_name_lenght
int product_description_lenght
int product_photos_qty
float product_weight_g
float product_length_cm
float product_height_cm
float product_width_cm
}
olist_sellers {
string seller_id PK
string seller_zip_code_prefix
string seller_city
string seller_state
}
olist_order_reviews {
string review_id PK
string order_id FK
int review_score
string review_comment_title
string review_comment_message
timestamp review_creation_date
timestamp review_answer_timestamp
}
olist_order_payments {
string order_id FK
int payment_sequential
string payment_type
int payment_installments
float payment_value
}
olist_geolocation {
string geolocation_zip_code_prefix
float geolocation_lat
float geolocation_lng
string geolocation_city
string geolocation_state
}
product_category_name_translation {
string product_category_name PK
string product_category_name_english UK
}
olist_marketing_qualified_leads {
string mql_id PK
date first_contact_date
string landing_page_id
string origin
}
olist_closed_deals {
string mql_id FK
string seller_id FK
string sdr_id
string sr_id
timestamp won_date
string business_segment
string lead_type
string lead_behaviour_profile
bool has_company
bool has_gtin
string average_stock
string business_type
string declared_product_catalog_size
string declared_monthly_revenue
}
olist_customers||--o{olist_orders:"places"
olist_geolocation||--o{olist_customers:"locates"
olist_orders||--|{olist_order_items:"contains"
olist_orders||--|{olist_order_payments:"paid_via"
olist_orders||--o{olist_order_reviews:"receives"
olist_products||--o{olist_order_items:"defines"
olist_sellers||--o{olist_order_items:"fulfills"
olist_geolocation||--o{olist_sellers:"locates"
product_category_name_translation||--o{olist_products:"translates_category"
olist_marketing_qualified_leads||--o|olist_closed_deals:"converts_to"
olist_closed_deals|o--||olist_sellers:"becomes_seller"
探索性数据分析与问题拆解
从北极星指标入手,同期群多维度观察,发现并层层拆解问题。
单纯的 GMV 只是一个随着时间不断增长的 “虚荣指标”,我们实际需要洞察的是它的(年/月/季度)变化率。
利用 olist_orders_dataset 和 olist_order_items_dataset 计算 GMV 变化率之前首先要审计和清洗数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
------------------------------------
olist_orders_dataset 审计结果
------------------------------------
alerts type count missing missing_pct unique unique_pct top top_cnt top_pct
column
order_id may_pk_or_uk | may_need_nlp object 99441 0 0.000000 99441 1.000000 00010242fe8c5a6d1ba2 1 0.000010
customer_id may_pk_or_uk | may_need_nlp object 99441 0 0.000000 99441 1.000000 00012a2ce6f8dcda20d0 1 0.000010
order_status too_many_top object 99441 0 0.000000 8 0.000080 delivered 96478 0.970203
order_purchase_timestamp may_pk_or_uk | may_need_nlp object 99441 0 0.000000 98875 0.994308 2017-11-20 10:59:08 3 0.000030
order_approved_at missing_need_handle | may_need_nlp object 99441 160 0.001609 90733 0.912430 2018-02-27 04:31:10 9 0.000091
order_delivered_carrier_date missing_need_handle object 99441 1783 0.017930 81018 0.814734 2018-05-09 15:48:00 47 0.000473
order_delivered_customer_date missing_need_handle | may_pk_or_uk | may_need_nlp object 99441 2965 0.029817 95664 0.962018 2016-10-27 17:32:07 3 0.000030
order_estimated_delivery_date object 99441 0 0.000000 459 0.004616 2017-12-20 00:00:00 522 0.005249
------------------------------------
olist_order_items_dataset 审计结果
------------------------------------
alerts type count missing missing_pct unique unique_pct top top_cnt top_pct min max mean median std zero zero_pct negative negative_pct skewness kurtosis
column
order_id object 112650 0 0.0 98666 0.875863 8272b63d03f5f79c56e9 21.0 0.000186 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
order_item_id check_polar_valid | high_skewed | may_high_kurt int64 112650 0 0.0 21 0.000186 NaN NaN NaN 1.00 21.00 1.197834 1.00 0.705124 0.0 0.0000 0.0 0.0 7.580356 103.857361
product_id object 112650 0 0.0 32951 0.292508 aca2eb7d00ea1a7b8ebd 527.0 0.004678 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
seller_id object 112650 0 0.0 3095 0.027474 6560211a19b47992c366 2033.0 0.018047 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
shipping_limit_date object 112650 0 0.0 93318 0.828389 2017-07-21 18:25:23 21.0 0.000186 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
price float64 112650 0 0.0 5968 0.052978 NaN NaN NaN 0.85 6735.00 120.653739 74.99 183.633928 0.0 0.0000 0.0 0.0 7.923208 120.828298
freight_value float64 112650 0 0.0 6999 0.062130 NaN NaN NaN 0.00 409.68 19.990320 16.26 15.806405 383.0 0.0034 0.0 0.0 5.639870 59.788253
存在一些缺失率低于 3% 的字段,不影响整体分析,无需处理。
在 TableauBI 中对 GMV 可视化处理后,可以明显发现 GMV 持续高波走低,经营情况不容乐观。
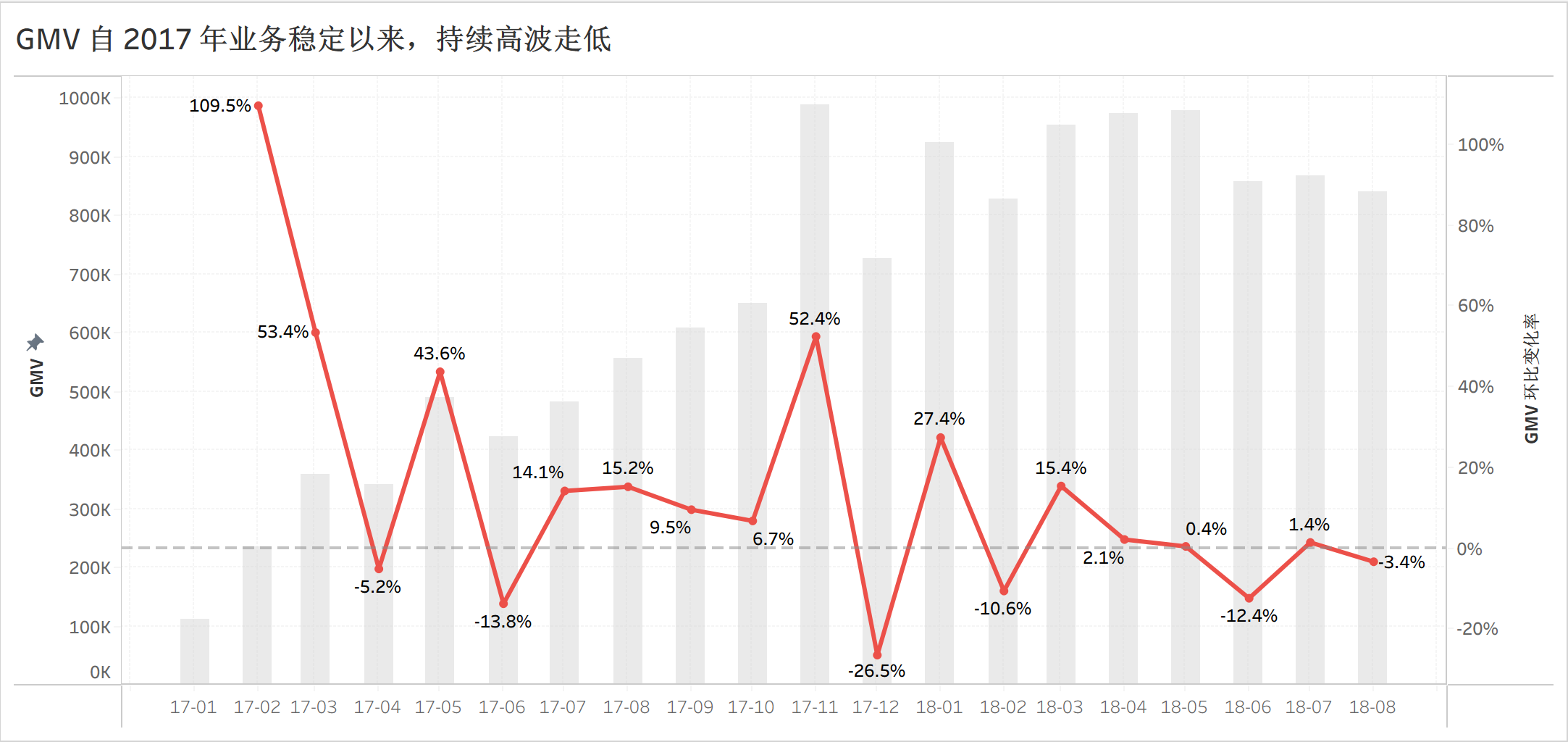
发现问题后,需要找问题根因,手段是进一步拆分 GMV,看到底是哪个子指标导致 GMV 持续走低。
这里的拆分方式有很多,但是根据 MECE 原则,我们一般优先把 GMV 拆分为 $订单量 \times 订单均价$。
对比订单量和订单均价与 GMV 的定基变化率,可以明显看到 GMV 几乎完全是由订单量驱动的。
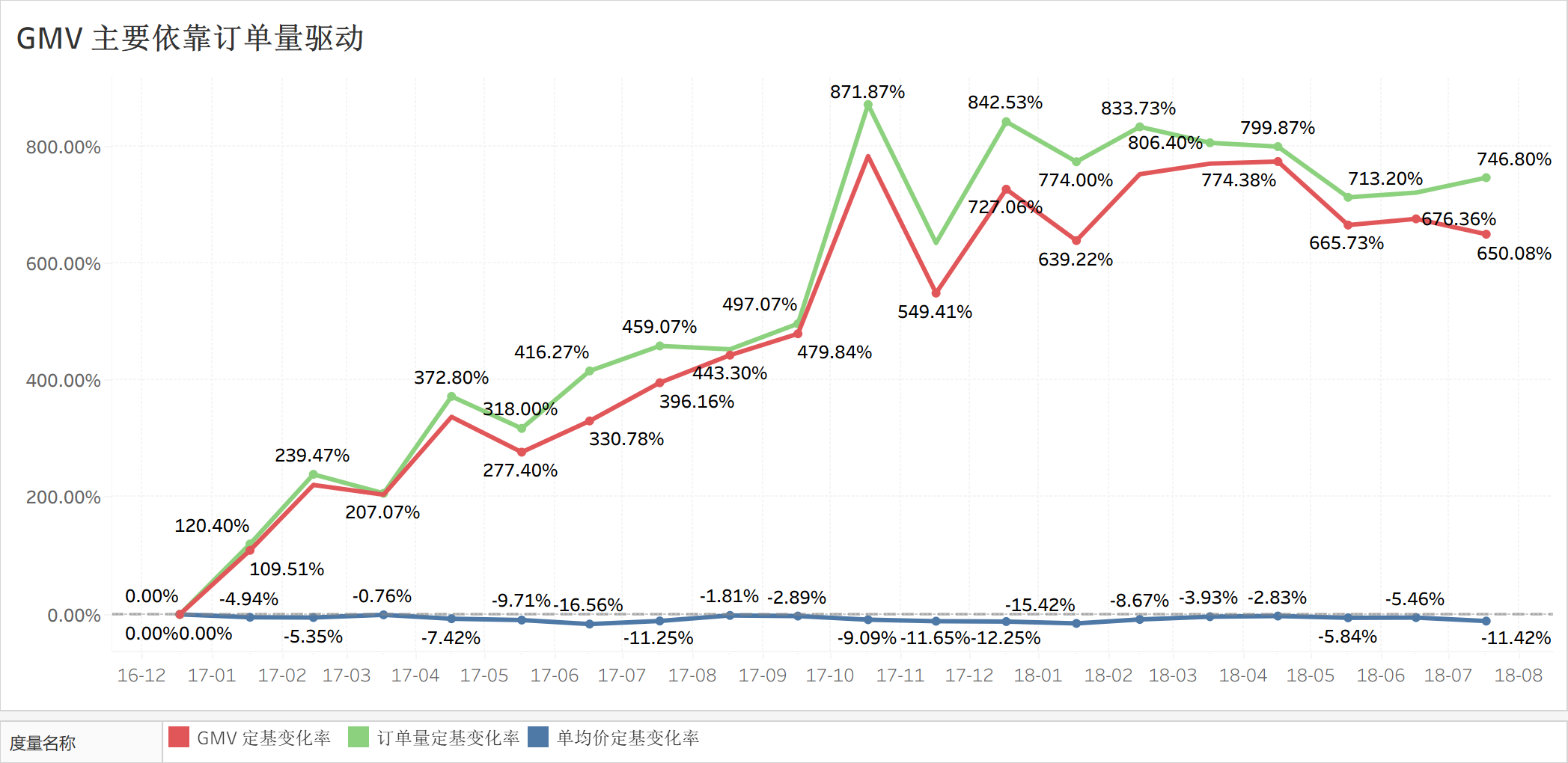
也就是说,GMV 的异常趋势主要是订单量出了问题。那为什么订单量会出问题。
考虑到 Olist 当时作为初创公司的背景,可以往两个方面考虑:新用户少了或者老用户走了。
所以我们可以进一步拆分:$订单量 = 新用户订单 + 老用户订单$
列出新老用户订单量的逐月占比,可以清晰地观察到,几乎所有订单都来自新用户,老用户复购比例极低。
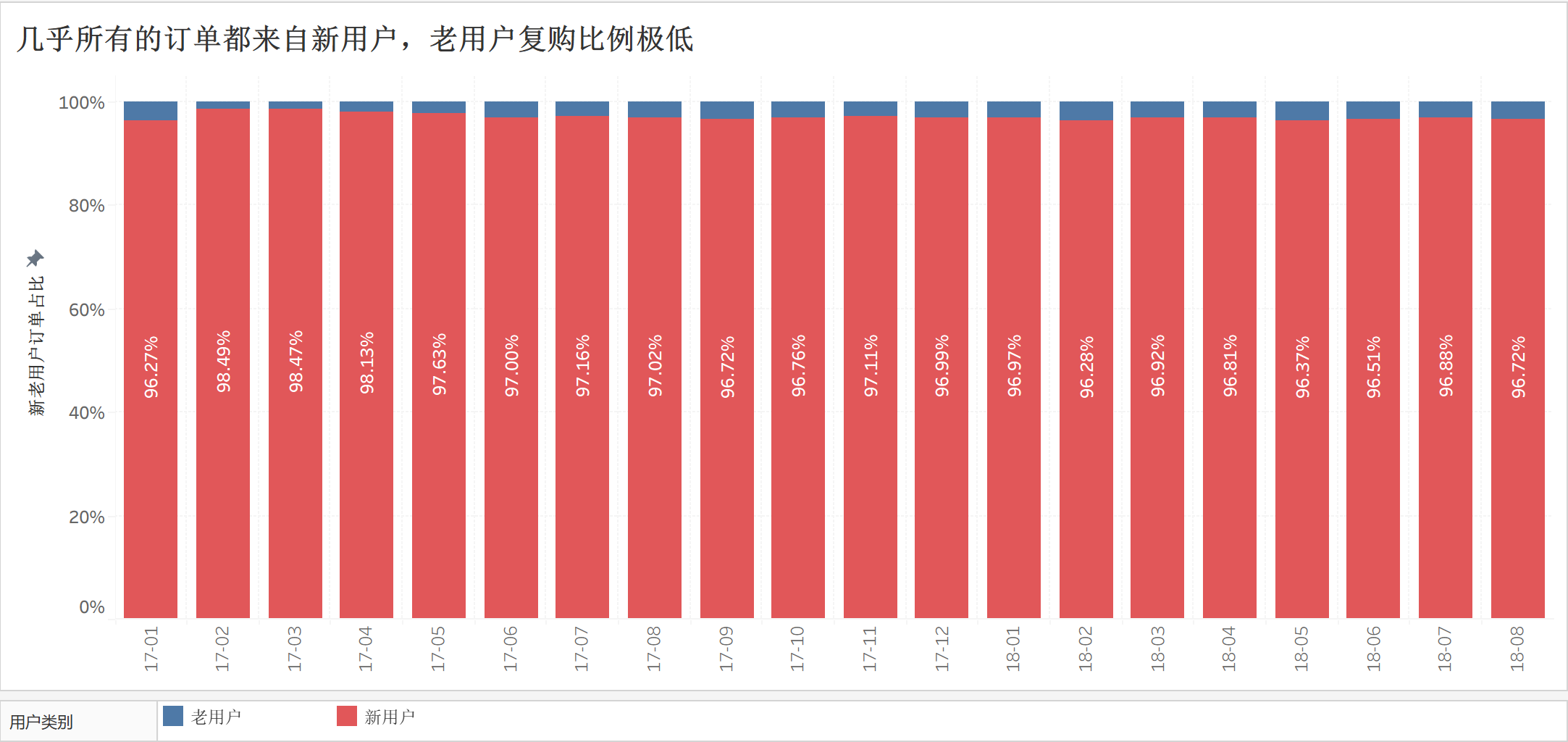
那现在的问题就更清晰了,新用户开发接近瓶颈,但老用户又留不下来。那用户为什么不复购呢?
用户不复购的理由无非就两种:商品本身不需要频繁复购或者购买体验差导致不愿意再复购。
对比新老用户的商品购买偏好,可以发现没有明显区别,但买的东西大多数都是耐用品,本身复购率就比较低。
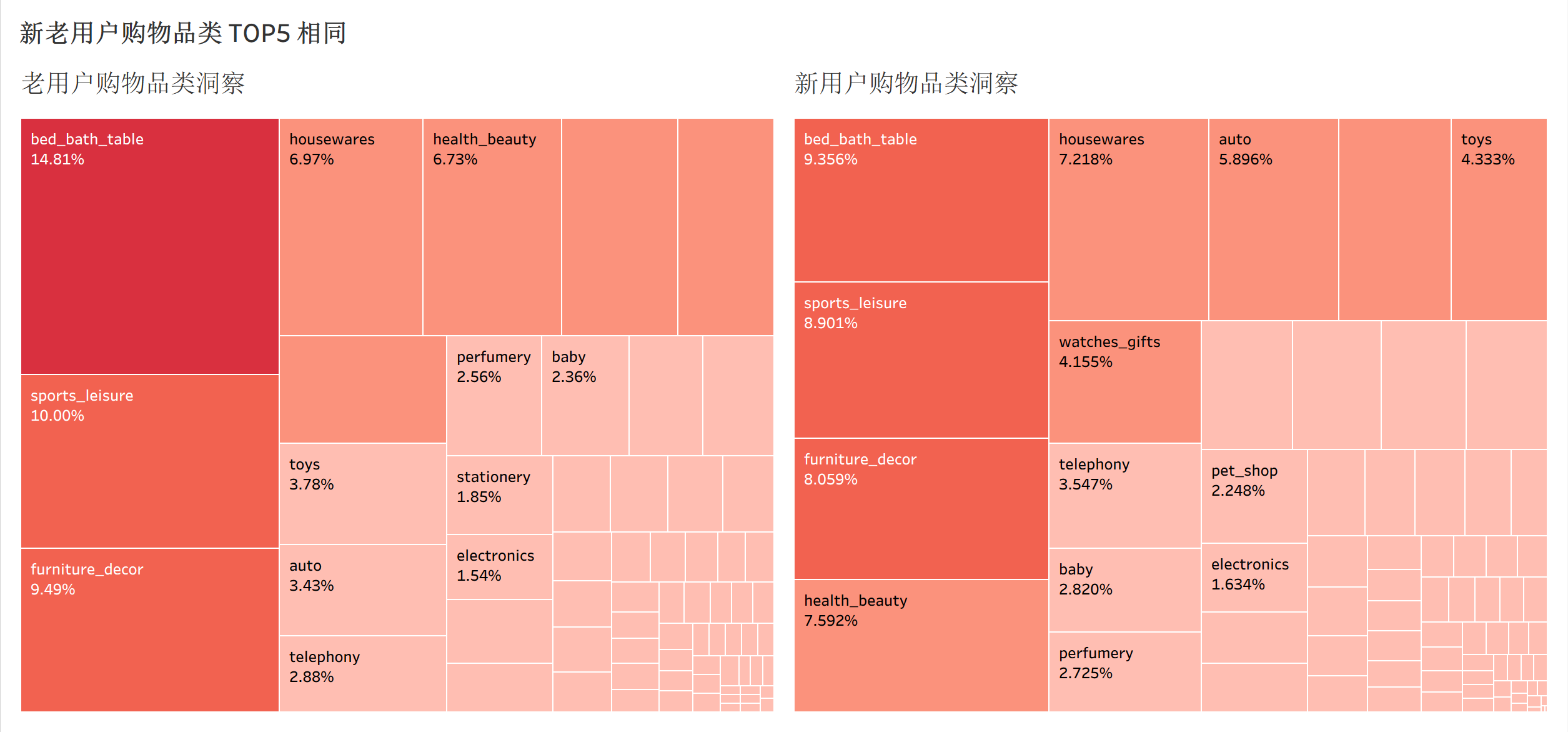
| 英文分类名 | 中文含义 | 产品属性 | 复购频率 |
|---|---|---|---|
| bed_bath_table | 床上用品、卫浴、桌布 | 半耐用品 | 低。一套床单或毛巾通常可以使用 1-2 年。 |
| sports_leisure | 运动与休闲(器材、服装) | 耐用品/消费品 | 中低。运动器材(如哑铃、帐篷)属于典型耐用品。 |
| furniture_decor | 家具装饰(灯具、挂饰等) | 硬耐用品 | 极低。装修或布置房间是一次性需求。 |
| health_beauty | 健康美容(仪器、化妆品) | 消费品 | 中。虽然护肤品是消耗品,但 Olist 上有很多是美容仪器。 |
| housewares | 家用器具(厨具、小家电) | 耐用品 | 低。锅铲、烤箱等家电除非损坏,否则很少复购。 |
另一方面,我们还要看看那些非满分评价主要是在抱怨什么。
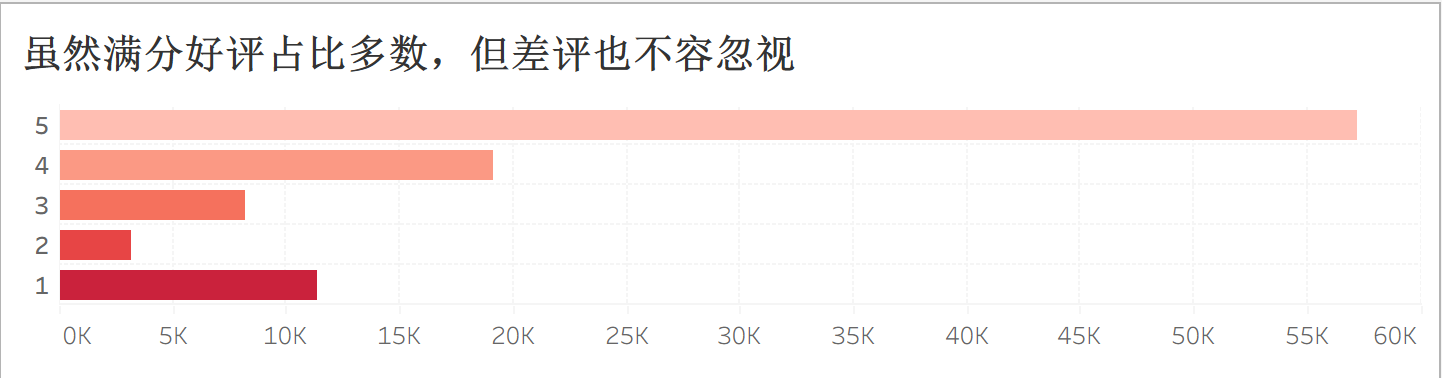
这里需要 NLP 接入进行情感分析,和主题词提取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
import os
import sys
# 配置 HuggingFace 镜像
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
import nltk
import pandas as pd
# 配置打印时不折叠字段
pd.set_option('display.width', None)
pd.set_option('display.max_columns', None)
from bertopic import BERTopic
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
def ensure_nltk_resources():
"""
确保 NLTK 资源存在,用于停用词处理
:return: None
"""
try:
nltk.find('corpora/stopwords')
except LookupError:
print('正在尝试下载 NLTK stopwords...')
try:
nltk.download('stopwords')
except Exception as e:
print(f'\nNLTK 资源下载失败:{e}')
sys.exit(1)
def sense_analysis():
"""
情感分析处理
:return: None
"""
print("--- 程序已启动,正在初始化,请稍候... ---")
# 1. 确保 NLTK 停用词可用
ensure_nltk_resources()
pt_stopwords = stopwords.words('portuguese')
# 剔除无意义的口水词
extra_stopwords = ['ol', 'bo', 'bababa', 'jjjj', 'io', 'td', 'ta', 'bommm']
pt_stopwords.extend(extra_stopwords)
# 2. 读取并清洗数据
reviews = pd.read_csv('./dataset/olist_order_reviews_dataset.csv')
reviews = reviews.dropna(subset=['review_comment_message'])
reviews = reviews[reviews['review_comment_message'].str.strip() != '']
reviews = reviews.loc[reviews['review_score'] < 5, :]
reviews['clean_text'] = reviews['review_comment_message'].str.lower()
print(f'评论清洗完成,有效评论量: {len(reviews)}')
# 3. 初始化 BERTopic
print('正在初始化 BERTopic 模型...')
vectorizer_model = CountVectorizer(stop_words=pt_stopwords)
topic_model = BERTopic(
language='multilingual',
embedding_model='sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2',
vectorizer_model=vectorizer_model,
verbose=True,
nr_topics='auto'
)
# 训练模型
topics, probs = topic_model.fit_transform(reviews['clean_text'])
# 4. 获取主题列表
topic_info = topic_model.get_topic_info()
print('\n主要主题列表 (Top 20):')
print(topic_info.head(20))
top_20_topics = topic_info.head(20).copy()
# 6. 导出结果
# 将主题 ID 映射回原始数据
output_path = './dataset/bad_reviews_top_topics.csv'
top_20_topics.to_csv(output_path, index=False)
print(f'\n结果已导出至: {output_path}')
if __name__ == '__main__':
sense_analysis()
| 主题 ID | 样本数量 | 主题标签 (Name) | 关键词 (Representation) | 代表性评论内容 (中译) |
|---|---|---|---|---|
| -1 | 8875 | 未分类/综合投诉 | 产品, 购买, 物流, 店铺, 收到, 期限 | “订单显示已送达但我没收到”, “提前送达且质量很好”, “只收到了两个中的一个” |
| 0 | 534 | 数量缺失 | 单位, 两件, 仅, 收到, 购买, 零件 | “买了2个单位只收到1个!!”, “我买了两个,结果只发了一个。” |
| 1 | 526 | 总体好评 | 好, 棒, 推荐, 不错, 喜欢, 顶级的 | “好”, “很好”, “非常推荐” |
| 2 | 507 | 提前送达(质量) | 提前, 快速, 期限, 收到, 质量 | “比预期提前送达,产品非常好!”, “产品提前到了。” |
| 3 | 410 | 配送时效 | 提前, 期限, 延迟, 准时, 延期 | “提前到货”, “在期限内送达”, “物流稍有延迟” |
| 4 | 371 | 包装破损 | 箱子, 错误, 压扁, 包装, 缺陷, 损坏 | “包装很差,箱子都压扁了”, “产品收到时包装盒是坏的。” |
| 5 | 346 | 颜色错误 | 颜色, 蓝色, 黑色, 错误, 粉色, 白色 | “颜色不对”, “买了粉色结果发了黑色。虽然产品不错但颜色错了。” |
| 6 | 341 | 优质/推荐 | 棒, 优秀, 质量, 漂亮, 推荐 | “产品很好”, “质量非常好的产品” |
| 7 | 289 | 逾期未达(日期) | 2018, 日期, 预计, 今天, 还没收到 | “预计27号送达,今天29号了还没收到!”, “一直没收到货也没发票。” |
| 8 | 285 | 邮局自提问题 | 家里, 邮局, 去取, 运费, 住宅 | “我付了送货上门的运费,却得自己去邮局取货!”, “产品没送到家。” |
| 9 | 258 | 手表类目 | 手表, 卡西欧, 表带, 女款, 盒子 | “手表非常好”, “没收到手表”, “手表没送达” |
| 10 | 234 | 订单查询/无回应 | 订单, 包裹, 还没, 联系, 没人 | “还没收到我的订单”, “联系不上客服,订单还没到” |
| 11 | 212 | 订单取消 | 取消, 申请, 没收到, 已经 | “逾期未送达我申请取消”, “没收到货也没要求取消”, “申请了取消结果还是发货了” |
| 12 | 182 | 状态正常 | OK, 一切正常, 正常, 顺利 | “一切 OK”, “全部正常”, “符合预期” |
| 13 | 167 | 性价比/有用 | 好, 比较, 价格, 柔软, 实用 | “非常好”, “非常实用”, “考虑到价格很不错” |
| 14 | 163 | 无法评价(未收到) | 还没, 收到, 目前, 无法评价 | “目前还没收到产品,无法给出评价”, “还没收到货” |
| 15 | 162 | 店铺推荐 | 店铺, 推荐, 棒, 购买, 恭喜 | “推荐这家店”, “店铺和产品都值得推荐” |
| 16 | 153 | 家具/椅子类 | 椅子, 靠背, 组装, 螺丝, 缺少 | “少发了一把椅子”, “椅子不错”, “买了5把目前只收到了4把” |
| 17 | 146 | 物流极速 | 快速, 效率, 速度, 超快, 服务 | “物流非常快”, “送货效率很高” |
| 18 | 138 | 退款/未收到 | 收到, 没收到, 退款, 完整 | “没收到产品”, “要求全额退款” |
使用 BERTopic 进行自然语言情感分析后,发现买家的抱怨主要集中在物流方面,我们需要进一步衡量物流指标。
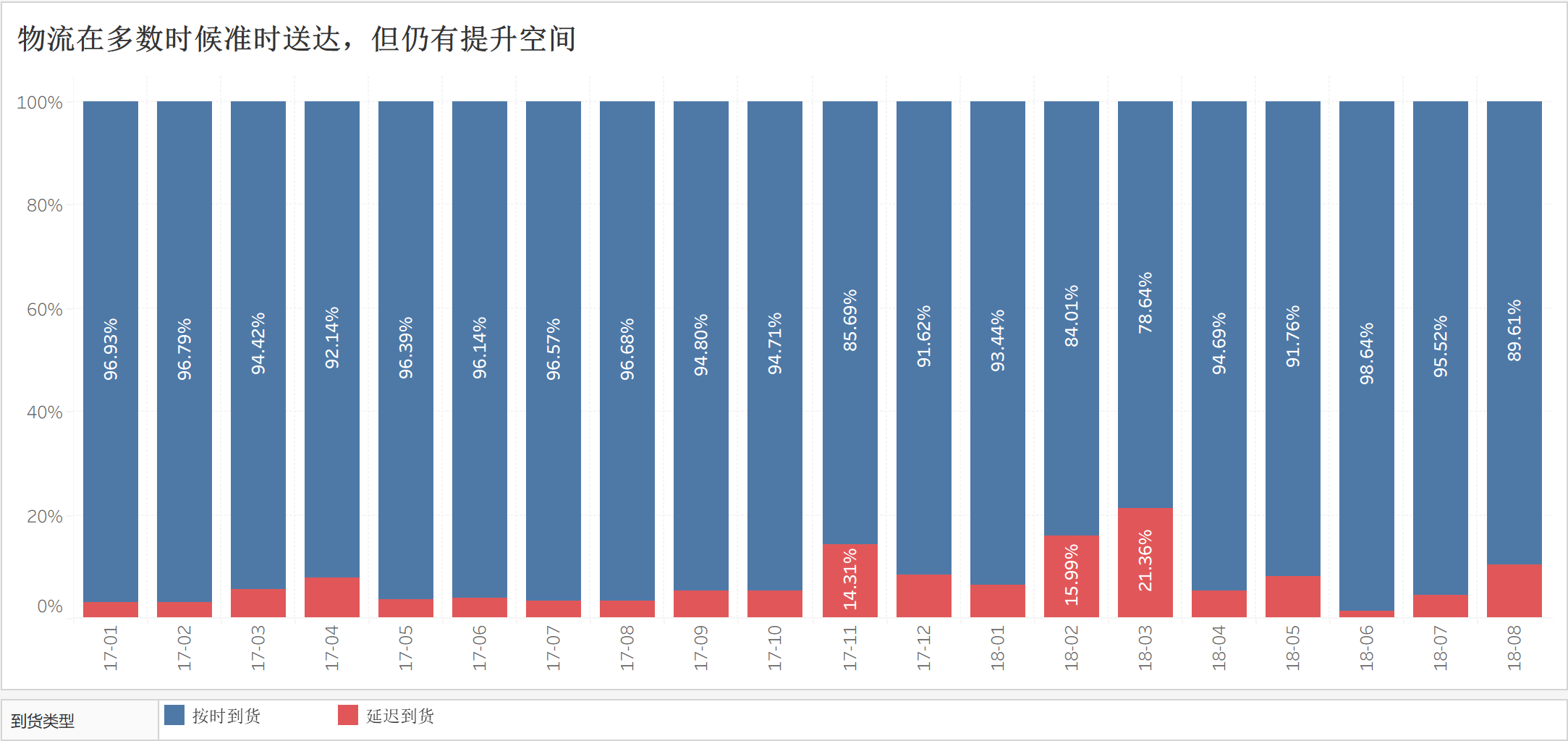
观察到,实际的数据没有预想的糟糕,多数时候还是可以准时送达的。
图中 17 年 11 月是黑色星期五,物流压力陡增导致延迟率上升;另外,18 年 2 月和 3 月是巴西物流工人大罢工,全国邮政基本停摆,属于不可抗力导致的物流延迟率上升。